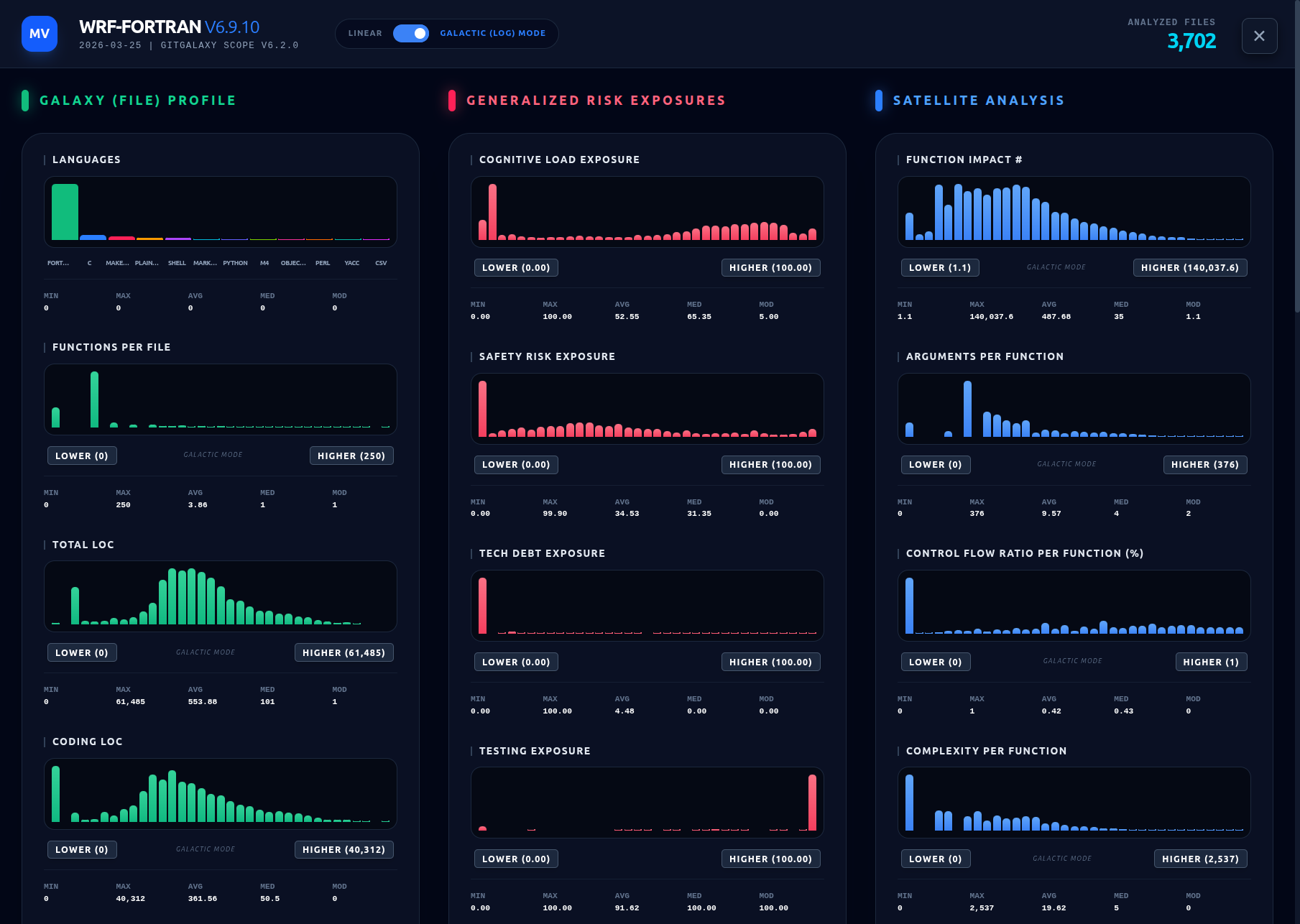
The blAST (Bypassing LLMs and ASTs) engine is a custom made knowledge graph engine that chunks repositories up at the function level and scores each function based on 50 unique metrics. It then rolls that data up to score each file and then rolls that data up to summarize the repo. By using a custom engine we are fully in control of what and how it searches. We built it so it doesn't require compilable code, that its fast and that it assess your entire repo. ASTs can't do that. ASTs are great for finding missing commas and memory overflows, they were not designed to be knowledge graph generators. They miss the forest for the trees. LLMs hallucinate if the context window gets to large and are probabilistic - you get different answers on different days. The blAST engine solves this. All languages have keywords, most have functions. We built a custom engine to treat code files like text files and scan for these keywords to build a true knowledge graph. This engine can keep up with you if you switch language mid file, it can fully assess your multi-language repo where the ratio of test files to coding files and repo structure all tell the engine invaluable information that AST-based knowledge graphs will never be able to give assess. Our scanning paradigm is fully transparent and customizable, any false positive or misclassified can be fixed; every assumption our system makes has been abstracted into a tunable variable (over 300). Think of this as a tunable telescope. You can query how many active API network nodes this code base produces, how many unique external imports, functions with concurrency risk, or files with extreme cognitive load, but in a sub-set of files, at a threshold hold you control, with dozens of unique white and black lists to reduce false positive fatigue. The system comes with smart defaults. It's been field tested on over a 1000 repos spanning 50+ coding languages and 250+ file extensions.
Core Technology
- Bypasses LLMs and rigid ASTs
- Doesn't care if code compiles
- AST-free
- Maps code by keyword regex profiles
- Eliminates LLM architectural hallucinations
- Eliminates LLM context windows
- Eliminates LLM probabilistic responses with large data
- Scans 50+ languages, 250+ extensions, folder aware
Extreme Velocity & Scale
- 100,000 LOC/sec code analysis
- 0.07 GB/sec raw log ingestion
- Full-system scans in minutes
- Zero data sampling required
- Eliminates compute bottlenecks
- 100% daily system coverage
Intelligence & Tracking
- Builds longitudinal knowledge graphs
- Tracks logic at the function level
- Monitors risk exposures over time
- Temporal code evolution tracking
Security & Deployment
- 100% air-gapped execution
- on-premise deployment
- Zero IP exfiltration risk
- Zero-trust processing model
How to use
- python based, pip install gitgalaxy
- CLI based
- output series of jsons and sqlite db
- jsons specifically for AI-agent summary report
- full sqlite3 db with all data for query and storage
Validation
- Population statistics from a 1000 repos
- Comparing 10 different DOOM ports at the function and architecture level
- How I used keyword patterns to automate the cleanup of COBOL repos to produce automated JCLs, DAGs, schemas
- How I used keyword patterns to convert COBOL repos to a from scratch translation to a compiling java shell
📖 Official Documentation: Read the full technical specifications, architecture blueprints, and the Taxonomical Equivalence Map at squid-protocol.github.io/gitgalaxy.
pip install gitgalaxyPoint the GalaxyScope at any local repository or ZIP archive. The engine runs entirely on your local machine—zero data is transmitted.
galaxyscope /path/to/your/local/repoOption A: CLI Report based jsons saved to your computer for different needs
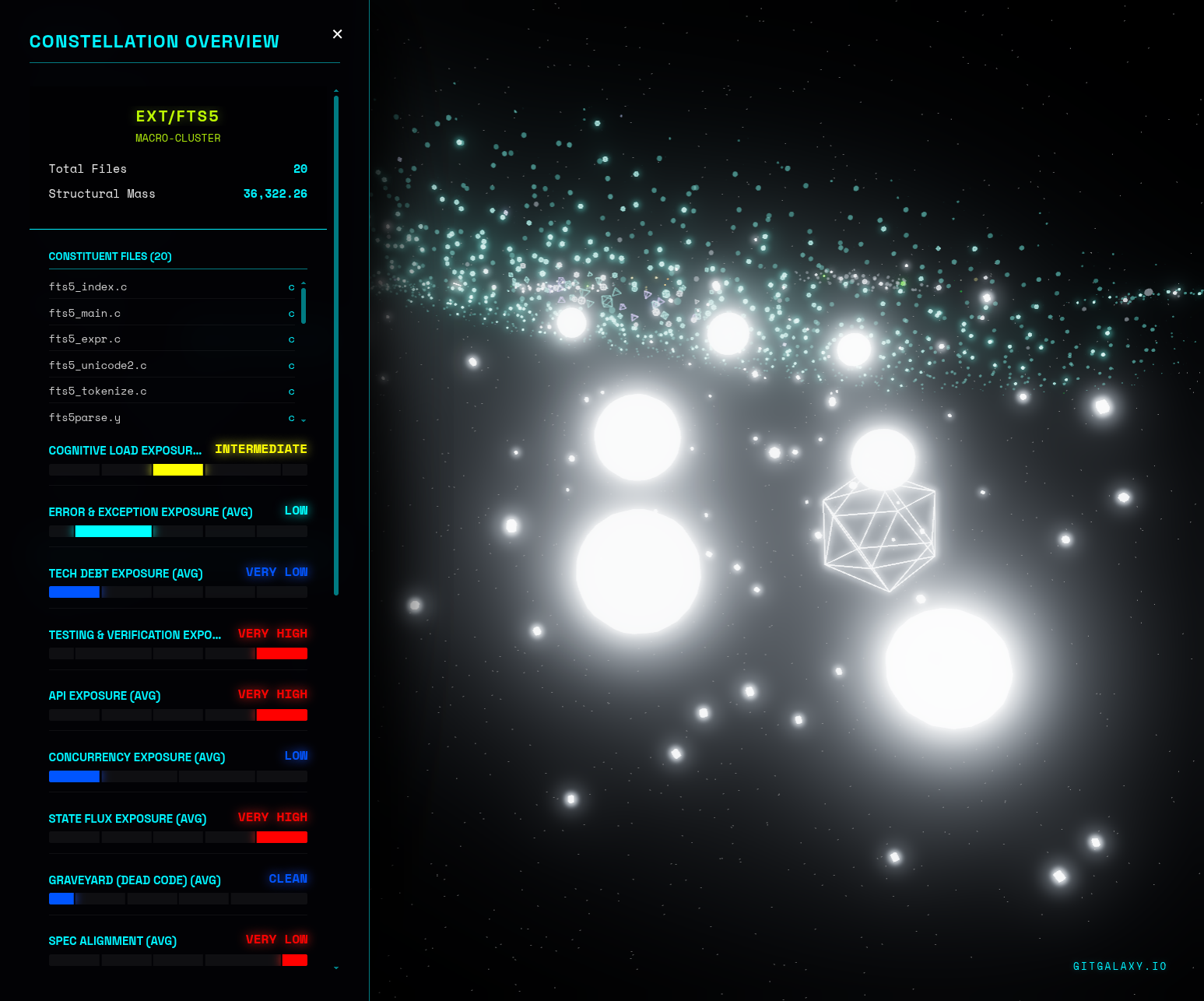
Option B: The Web Viewer (Frictionless) If you like art things, I made a non-numerical dash board where each file is a star and it's size and color correspond to risk metrics.
Simply drag and drop your generated "your_repo_GPU_galaxy.json" file (or a .zip of your raw repository) directly into GitGalaxy.io. All rendering and scanning happens entirely in your browser's local memory.
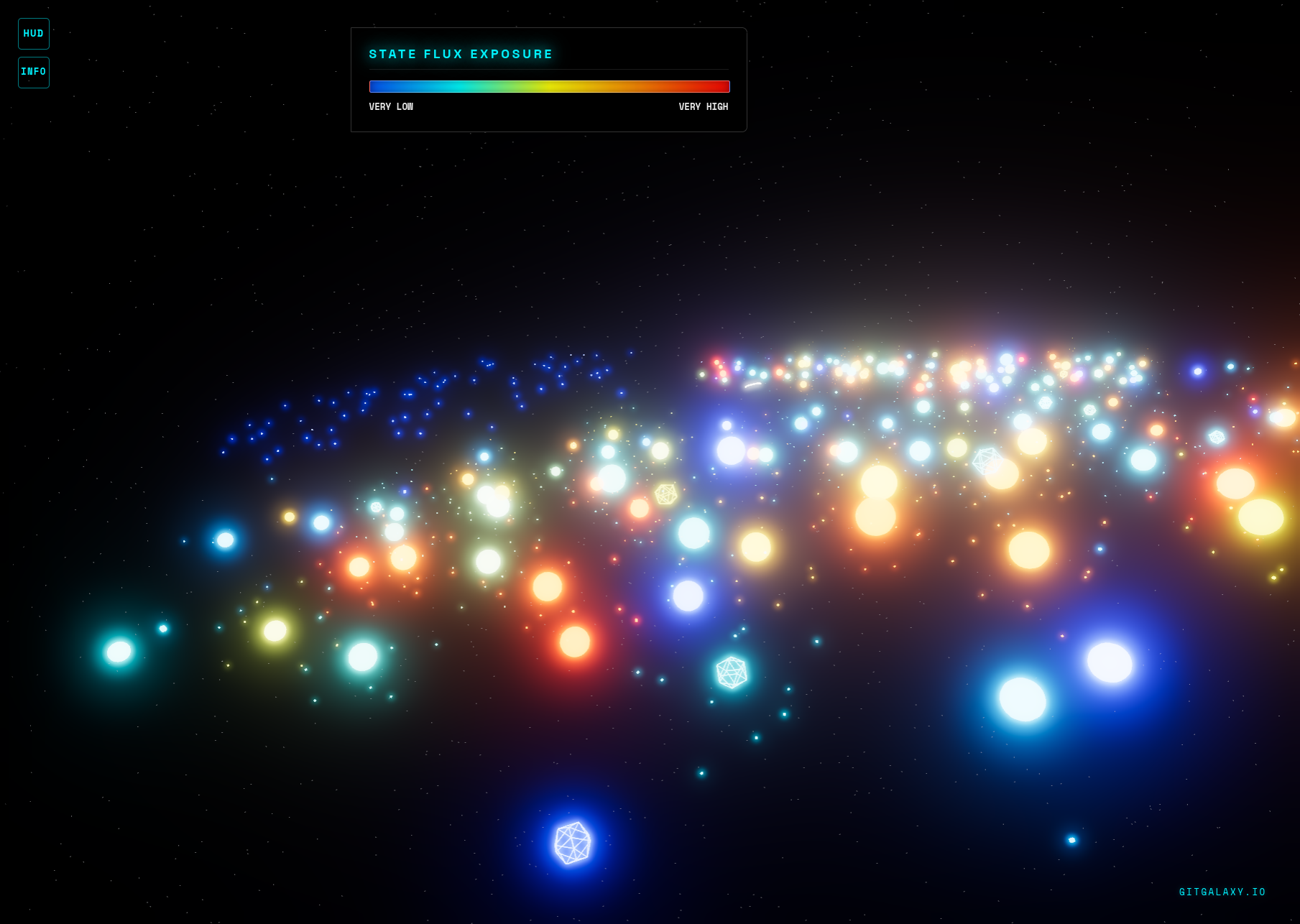

Your code never leaves your machine. GitGalaxy performs 100% of its scanning and vectorization locally.
- No Data Transmission: Source code is never transmitted to any API, cloud database, or third-party service.
- Ephemeral Memory Processing: Repositories are unpacked into a volatile memory buffer (RAM) and are automatically purged when the browser tab is closed.
- Privacy-by-Design: Even when using the web-based viewer, the data remains behind the user's firewall at all times.
Copyright (c) 2026 Joe Esquibel
GitGalaxy is released under the PolyForm Noncommercial License 1.0.0. It is completely free for personal use, research, experiment, testing, and hobby projects. Use by educational or charitable organizations is also permitted.
Any commercial use or integration into commercial SaaS products or corporate CI/CD pipelines requires a separate commercial license. Please reach out via gitgalaxy.io to discuss commercial integration.